on
Web scraping; example of extracting data from a long, messy & unstructured PDF file
In this post I am presenting an example of how, using web scrapping and data carpentry techniques, I extracted data from a messy and unstructured PDF published by the Spanish Government. See the repository of the code in GitHub.
In early 2021, the Government of Spain made public the list of all the properties that the Catholic Church registered between 1998 and 2015. The lists were published in PDF formatted documents of more than 3,000 pages. Apart from being a long PDF, the tables contained in the document were unstructured (almost each table was different from each other). So analyzing this data was a real challenge. Using web scraping techniques in R, I converted the data to a more friendly format and made an interactive search engine that facilitates its access.
| Original format of the data | Interactive search enginge |
|---|---|
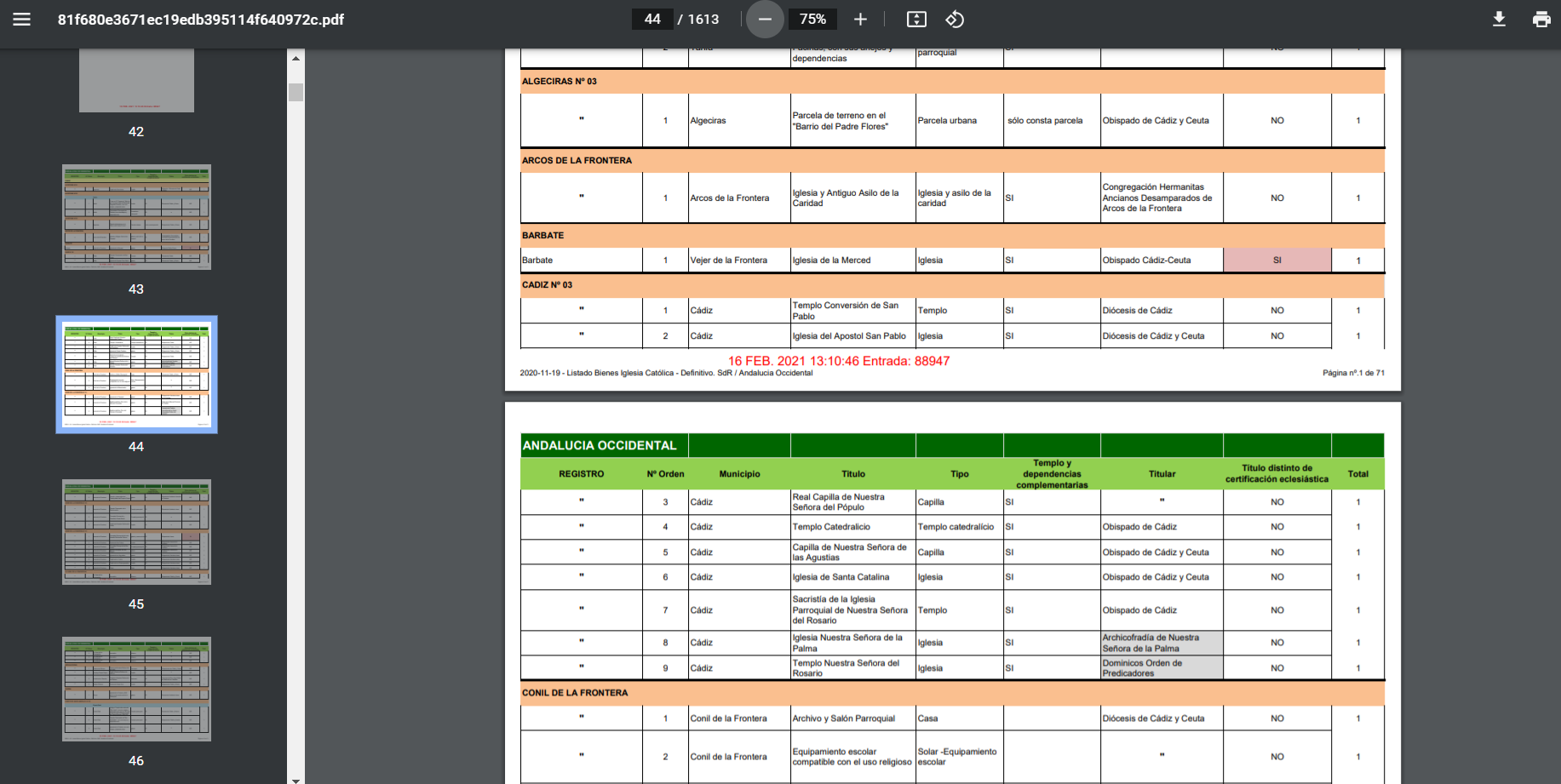 |
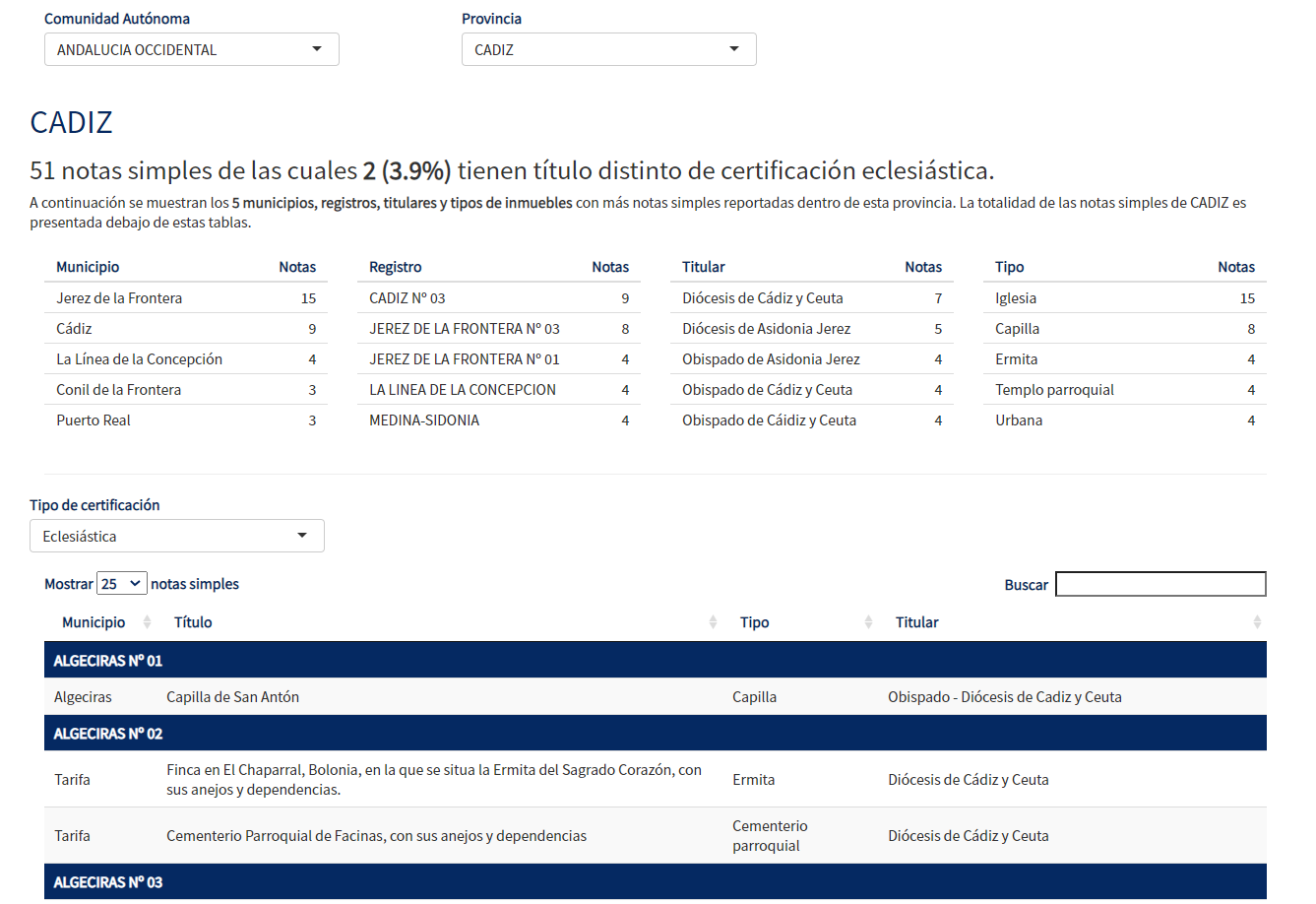 |
There are some important lessons learned from this process that are worth taking into consideration for any web scraping job:
Take time to inspect the data, try to identity patterns that will help you to convert the data into a tidy format: look for columns containing only capital letters, check if there is a consistency in the sequential order of things, etc.
Although an automate process is ideal, try to see if you can chunk your code: Is it possible to do a pre cleaning of the data? Would a semi-manual task can be done before coding?
This applies for any workflow: be super organized with your code; never repeat your self, comment WHY you are doing what your are doing.
Do not try to solve the puzzle at once. It may be worth to start little by little and then move to the big picture once the mystery has been solved!